百度seo引流揭秘,轻松获取精准流量
1005
2218
3625
管理员
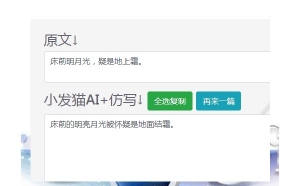
nlp智能语义处理伪原创
phpcms安装小发猫伪原创方法
dvbbs安装小发猫伪原创方法
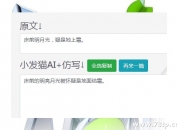
火车头小发猫ai伪原创,基于小发猫ai 智能写
火车头伪原创插件,基于小发猫ai 智能写作
微信营销加好友的一个技巧
本版积分规则 发表回复 回帖后跳转到最后一页
|伪原创工具|论文降重|小学作文|读后感|毕业论文|凯发app官网登录-凯发app官方网站 ( )"));
gmt 8, 2023-10-21 03:26 , processed in 0.048476 second(s), 27 queries .
powered by discuz! x3.4
© 2001-2017 comsenz inc.



 发表于 2019-12-27 18:28:43
发表于 2019-12-27 18:28:43